Crawling en indexatie stappenplan: een compacte aanpak voor betere vindbaarheid
Wie zoekt op crawling en indexatie stappenplan, wil meestal geen uitgebreid technisch verhaal. De echte vraag is vaak praktischer: hoe controleer je in de juiste volgorde of zoekmachines je belangrijkste pagina’s goed kunnen vinden en indexeren?
Dat is een belangrijke vraag, want veel websites verliezen zichtbaarheid zonder dat de inhoud het probleem is. Pagina’s bestaan wel, maar worden slecht ontdekt, geven tegenstrijdige signalen af of komen uiteindelijk niet in de index. Dan blijft SEO-potentieel onbenut, ook als de content op zichzelf sterk is.
Voor websites die werken met een pillar-and-cluster model is dit extra relevant. Je wilt dat zoekmachines niet alleen losse pagina’s zien, maar ook begrijpen welke onderwerpen centraal staan en hoe ondersteunende content daarbij hoort. Een goed crawling en indexatie stappenplan helpt om die basis systematisch te beoordelen.
Wat zijn crawling en indexatie?
Crawling is het proces waarbij zoekmachines URL’s ontdekken en bezoeken. Dat gebeurt via interne links, XML-sitemaps, externe links en eerder bekende pagina’s. Tijdens dat bezoek verzamelt Google signalen over de inhoud, structuur en technische staat van een pagina.
Indexatie is de stap daarna. Dan beslist Google of een pagina wordt opgenomen in de zoekindex en dus in aanmerking komt om te verschijnen in de zoekresultaten.
Die twee processen hangen samen, maar zijn niet hetzelfde. Een pagina kan wel gecrawld worden en toch niet geïndexeerd raken. Andersom kan een URL bekend zijn bij Google, terwijl de verkeerde versie wordt gekozen voor opname in de index.
Waarom crawling en indexatie belangrijk zijn
Zonder crawling ontdekt Google je pagina’s niet goed. Zonder indexatie kunnen die pagina’s niet ranken. Dat maakt crawling en indexatie een basisvoorwaarde voor organische zichtbaarheid.
Daarnaast bepalen deze processen ook welke pagina’s binnen je website prioriteit lijken te hebben. Zoekmachines leiden dat af uit signalen zoals interne links, sitemap-opname, canonicalisatie en algemene structuur. Daarom raken crawling en indexatie niet alleen aan techniek, maar ook aan sitearchitectuur en contenthiërarchie.
Voor een website die topical authority wil opbouwen, is dat essentieel. Hoofdonderwerpen en ondersteunende pagina’s moeten technisch logisch met elkaar verbonden zijn.
Hoe crawling en indexatie werken
In grote lijnen verloopt het proces in drie stappen. Eerst ontdekt Google een URL. Daarna wordt die pagina gecrawld en beoordeeld op technische en inhoudelijke signalen. Vervolgens beslist Google of de pagina wordt geïndexeerd, en zo ja, welke versie de voorkeur krijgt.
Problemen kunnen op elk van die momenten ontstaan. Een pagina kan moeilijk te vinden zijn, wel gevonden maar op noindex staan, of technisch toegankelijk zijn maar toch niet als primaire versie worden geïndexeerd door dubbele URL’s of onduidelijke canonicals.
Juist daarom werkt een goed stappenplan van basis naar detail.
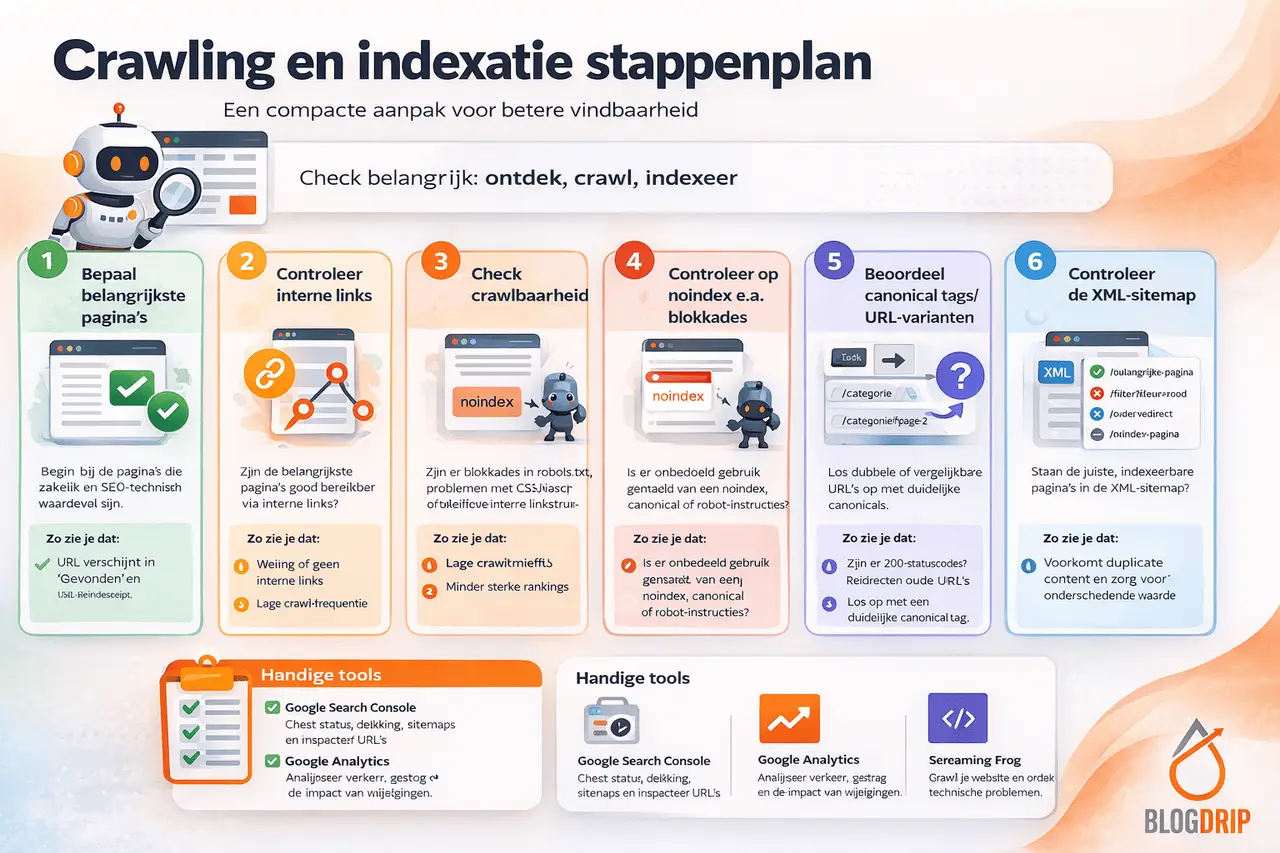
Crawling en indexatie stappenplan
Stap 1: bepaal welke pagina’s het belangrijkst zijn
Begin niet met alle URL’s op je website. Dat maakt de analyse onnodig breed. Stel eerst vast welke pagina’s zakelijk en SEO-technisch het belangrijkst zijn. Meestal gaat het om categoriepagina’s, dienstenpagina’s, pillar pages of andere strategische landingspagina’s.
Door eerst prioriteit aan te brengen, voorkom je dat elk technisch issue even belangrijk lijkt.
Stap 2: controleer of belangrijke pagina’s intern goed bereikbaar zijn
Belangrijke pagina’s moeten logisch bereikbaar zijn via navigatie, categorieën en contextuele interne links. Een pagina die diep in de site verstopt zit of nauwelijks interne ondersteuning krijgt, geeft een zwakker signaal af.
Interne links zijn daarom niet alleen handig voor gebruikers, maar ook een kernsignaal voor crawling en prioriteit.
Stap 3: kijk of de pagina’s crawlbaar zijn
Controleer daarna of zoekmachines de pagina’s technisch kunnen bezoeken. Denk aan blokkades via robots.txt, technische fouten of renderproblemen waardoor belangrijke content en links niet goed zichtbaar zijn.
Bij de meeste websites zit het probleem niet in een volledige blokkade, maar in beperkte crawlkwaliteit. Bijvoorbeeld wanneer content pas laat wordt geladen of interne links slecht in de HTML-structuur zitten.
Stap 4: controleer indexeerbaarheid
Een pagina kan perfect bereikbaar zijn en toch niet in Google verschijnen. Kijk daarom of belangrijke pagina’s geen onbedoelde noindex-tag hebben en technisch beschikbaar zijn voor indexatie.
Dit is een van de meest voorkomende oorzaken van gemiste zichtbaarheid, vooral na migraties, templatewijzigingen of CMS-updates.
Stap 5: beoordeel canonical tags en URL-varianten
Bestaan er meerdere URL-varianten met vergelijkbare inhoud, bijvoorbeeld door parameters, filters of CMS-routes? Dan moet duidelijk zijn welke versie leidend is.
Canonical tags helpen daarbij, maar alleen als andere signalen hetzelfde ondersteunen. Een canonical naar URL A werkt zwakker als interne links naar URL B wijzen en de sitemap URL C bevat.
Stap 6: controleer de XML-sitemap
Een XML-sitemap hoort belangrijke, indexeerbare URL’s te bevatten. Kijk dus of de juiste pagina’s erin staan en of de sitemap geen redirects, noindex-pagina’s of irrelevante varianten bevat.
Een sitemap vervangt geen interne linkstructuur, maar ondersteunt crawling en indexatie wel.
Stap 7: controleer statuscodes en redirects
Belangrijke pagina’s moeten een correcte 200-status teruggeven. Oude URL’s moeten logisch doorverwijzen als ze vervangen zijn. Redirectketens, loops en soft 404’s maken het zoekmachines onnodig lastig.
Deze stap is vooral belangrijk na migraties, URL-wijzigingen of opschoning van oude content.
Stap 8: kijk naar overlap en inhoudelijke waarde
Niet elk indexatieprobleem is puur technisch. Soms wordt een pagina wel gecrawld, maar niet geïndexeerd omdat de inhoud te veel overlapt met andere pagina’s of te weinig onderscheidend is.
Daarom hoort een compact crawling en indexatie stappenplan ook een inhoudelijke controle te bevatten. Niet uitgebreid, maar wel scherp genoeg om duplicatie en overlap te signaleren.
Stap 9: controleer mobiele rendering en performance
Pas wanneer crawling, indexatie en URL-logica grotendeels kloppen, kijk je naar performance en rendering. Belangrijke content moet mobiel goed zichtbaar zijn en technisch stabiel laden.
Dit is meestal niet de eerste oorzaak van grote indexatieproblemen, maar wel een relevante verdiepingsstap.
Stap 10: kijk naar patronen in plaats van losse URL’s
Als de belangrijkste pagina’s zijn gecontroleerd, kijk dan breder naar patronen. Ontstaan problemen op template-niveau? Genereert het CMS onnodige filter- of parameterpagina’s? Raken bepaalde URL-typen onbedoeld in de index?
Hier zit vaak de grootste structurele winst, vooral op grotere websites.
Veelgemaakte fouten
Een veelgemaakte fout is crawling en indexatie behandelen als hetzelfde. Daardoor wordt een probleem verkeerd ingeschat. Een pagina die niet zichtbaar is, hoeft geen crawlprobleem te hebben. Het kan ook een indexatie-, canonicalisatie- of overlapprobleem zijn.
Een tweede fout is werken zonder prioriteit. Dan worden alle URL’s even belangrijk behandeld, terwijl de echte impact meestal op een beperkte set kernpagina’s zit.
Ook zie je vaak dat websites te veel irrelevante URL’s genereren. Dat leidt tot technische ruis en maakt het moeilijker om de focus op belangrijke pagina’s te houden.
Praktische aanpak
Wie dit crawling en indexatie stappenplan goed wil gebruiken, begint met een kleine selectie prioriteitspagina’s. Controleer eerst of die intern goed bereikbaar, technisch crawlbaar en indexeerbaar zijn. Kijk daarna pas naar canonicals, sitemap-opname en URL-varianten.
Werk vervolgens van individueel naar patroon. Als dezelfde problemen op meerdere pagina’s terugkomen, ligt de oorzaak vaak in een template of systeeminstelling.
Het belangrijkste is dat je niet alles tegelijk probeert op te lossen. Begin bij wat de zichtbaarheid van belangrijke pagina’s direct belemmert.
Wanneer zie je resultaat?
Dat hangt af van het type probleem. Een onbedoelde noindex op een belangrijke pagina kan relatief snel effect hebben zodra die wordt verwijderd. Problemen met architectuur, dubbele URL’s of inconsistente canonicals hebben meestal meer tijd nodig, omdat zoekmachines die signalen opnieuw moeten verwerken.
Daarom is een crawling en indexatie stappenplan geen snelle groeitruc, maar een methode om de technische voorwaarden voor organische zichtbaarheid structureel te verbeteren.
Conclusie
Een goed crawling en indexatie stappenplan helpt om technische SEO terug te brengen tot de juiste volgorde. Eerst bepaal je welke pagina’s belangrijk zijn. Daarna controleer je of die pagina’s goed ontdekt, correct gecrawld en technisch indexeerbaar zijn. Pas daarna kijk je naar verfijning, patronen en schaalbaarheid.
De kern is eenvoudig: zoekmachines moeten zonder verwarring kunnen zien welke pagina’s op je website de hoofdrol spelen. Zodra crawling, indexatie, interne links en URL-signalen die duidelijkheid ondersteunen, wordt de technische basis van je website merkbaar sterker.